
“Countdown” numbers game: the lowdown
01 May 2016A lot has been written about Countdown. The longest-running game show on British TV, it’s been around for over 30 years and is apparently not going anywhere anytime soon.
If you never watched afternoon telly while having a sip of tea, Wikipedia will enlighten you about the show’s familiar format:
The two contestants in each episode compete in three disciplines: ten letters rounds, in which the contestants attempt to make the longest word possible from nine randomly chosen letters; four numbers rounds, in which the contestants must use arithmetic to reach a random target number from six other numbers; and the conundrum, a buzzer round in which the contestants compete to solve a nine-letter anagram.
Every now and then, neither contestant will succeed in getting precisely at the target in the alloted 30 seconds. In that case Rachel, the show’s resident math whiz, will offer a solution of her own for the audience’s arithmetic delight.
It’s a Numbers game
Naturally, the numbers round is my favorite part. My approach to watching TV (leaving it on while I do other, more important stuff) is not too conducive to solving the challenges in real-time, but over time I started to give more thought about a few particularly interesting instances.
 Rachel smiling discreetly after solving a game the contestants couldn’t. Because pointing and laughing on TV is officially considered Not British®.
Rachel smiling discreetly after solving a game the contestants couldn’t. Because pointing and laughing on TV is officially considered Not British®.
Rules
- There are 20 “small number” cards available (numbers 1 to 10, 2 cards of each) and 4 “large number” cards available (25, 50, 75, 100);
- 6 cards will be drawn. It’s possible to choose how many large numbers you get, from 0 to 4. The remaining ones will be small numbers;
- All cards within each category are drawn at random, with uniform probability;
- The target is a 3-digit number from 100 to 999, picked at random with uniform distribution (the actual possibility of getting a target of exactly 100 is debated, but we’ll assume it’s possible);
- Only the 4 elementary mathematical operations are allowed (
+ - * /); - You can use as many of the 6 input numbers as you want, but can only use each number once;
- All operations must result in integers.
Points
Points are awarded to the contestant which gets closest to the target number, in the following manner:
- 10 points if the target was hit exactly;
- 7 points if the result is within a distance of 1 to 5 from the target;
- 5 points if the result is within a distance of 6 to 10 from the target;
- 0 otherwise.
The 952
We will take James Martin’s famous 952 game as an example. He asked for 4 large numbers and 2 small ones, and got this:
3 6 25 50 75 100
Target: 952
The somewhat surprising solution he proposed was
100 + 6 = 106
* 3 = 318
* 75 = 23,850
- 50 = 23,800
/ 25 = 952
The intermediate result 23,850 was astonishing because it’s uncommon for contestants to (successfully) resort to such large numbers in a calculation. An alternate solution could be:
6 * 75 = 450
/ 50 = 9
* (100 + 3) = 927
+ 25 = 952
Some people felt Martin set himself up for a difficult calculation because he asked for 4 large numbers, which supposedly gives you a harder game than picking 2 or 3. Also, from time to time neither of the contestants can find a spot-on solution, and every now and then even Rachel is unable to find one.
All this got me thinking how possible it actually is to solve a Countdown numbers game. How many of them are unsolvable? Does solvability depend on how many large numbers you get? Or is the target set by the machine the most important factor?
I decided all these questions will be answered by some code. Let the (numbers) games begin!
Solution representation
In our quest for answers, the first question to be asked is how to represent an instance of a possible solution inside the computer. Say we want to represent James Martin’s 952 solution in infix notation (the notation we normally use when writing math by hand):
((((100 + 6) * 3) * 75) - 50) / 25
We could simply put the numbers and operators in a list, interpret and calculate the first subsequence [number operator number], replacing it with the operation result, repeat the procedure, and so on. Eventually we will get our result:
[100 + 6 * 3 * 75 - 50 / 25]
[106 * 3 * 75 - 50 / 25]
[318 * 75 - 50 / 25]
[23850 - 50 / 25]
[23800 / 25]
[952]
This looks all well and good, but let’s try with our alternate solution now:
[6 * 75 / 50 * 100 + 3 + 25]
[450 / 50 * 100 + 3 + 25]
[9 * 100 + 3 + 25]
[900 + 3 + 25]
[903 + 25]
[928]
Oops. What happened here is that the operation order we originally set was not respected, because we actually had a pair of parentheses around 100 + 3. For such an infix representation to work as expected, we have to also represent the parentheses – or some equivalent mechanism that will let us dictate the precise order of the operations. Without that, our simple list is limited in the solutions it can represent.
We could add parentheses to our representation, but this would unnecessarily complicate not only the representation logic but also the topology of our search space (more on that later). A much better solution is available: using postfix notation.
RPN
Postfix, also known as Reverse Polish Notation (RPN), is able to represent our operations in any order we desire, without ambiguities and with no need to resort to parentheses. This makes it a more appealing choice for our application.
In RPN we interpret each subsequence [number number operator] as an operation. So, if we wanted to divide 100 by 5, we could write 100 5 / to obtain 20.
Let’s see how our 952 alternate solution looks now.
[6 75 * 50 / 100 3 + * 25 +]
[450 50 / 100 3 + * 25 +]
[9 100 3 + * 25 +]
[9 103 * 25 +]
[927 25 +]
[952]
You probably noticed that at some point we had three numbers (9, 100, 3) before an operator (+). This is OK, because the operator only acts on the two numbers just before it: (100 3 +) = 103. Number 9 is further down the stack; it sits there patiently while 100 and 3 are being operated on, and only gets used afterwards.
Search
I decided to KISS and use a brute-force search. Given a game composed of 6 numbers, all legal solutions will be tried until either we exhaust the pool of legal solutions, or we already have at least one solution covering each possible target. Some optimizations were made in the form of abandoning the current solution in these cases:
- We get an intermediate result equal to zero. This is possible because any result given by such a solution can be obtained more simply by eliminating the operations which created the zero;
- The same goes for a multiplication/division with an operand of 1;
- And the same can be said for an intermediate negative result (changing the order of previous operations will eliminate any negatives).
A language for solutions
In RPN, an operator needs at least 2 numbers just below it in the stack. Moreover, in the end we want the stack to have one number, and nothing else (our final result). Therefore, given 6 numbers and 5 operators, not all permutations of these elements will make a well-formed RPN sequence. In other words, while using numbers and operators to form a possible solution, there is a language we have to adhere to.
Let’s call the symbols of our language N (number) and O (operator). Knowing RPN rules, we can obtain the only legal word with 2 numbers and 1 operator:
N N O
We are not still considering whether the number is a large or small one, or which operator exactly O represents. No matter these choices, we know ONN and NON would not be possible because in RPN the operator needs 2 numbers just before it. NNO is the only legal choice.
To extend this result for longer words, it’s useful to recognize that:
- In each word prefix, we need to have more numbers than operators;
- Considering the previous rule and that we must end with exactly one number, if the whole word has a certain number
nof operators, it has to haven+1numbers exactly; - All legal words will start with two numbers and end with one operator.
We can give our language better grounding by giving our N token a value of +1, and O gets a value of -1. We will call X[i] the ith prefix sum of our word. Therefore (for a word of length l) our previous rules become simply:
X[l]must equal 1X[i]can never be less than 1 for all i
This imposes the following format:
N N {K} O
where {K} represents 0 to 4 pairs of one N and one O, in any order which follows the language rules.
From 0 to 4 extra pairs of {N, O}, we can progressively build the language of legal words for our application:
- 0 pairs: 1 possible word (
NNO) - 1 pair: 2 possible words (
NNONO,NNNOO) - 2 pairs: 5 possible words (
NNNNOOO,NNNONOO,NNNOONO,NNONNOO,NNONONO) - 3 pairs: 14 possible words (
NNNNNOOOO,NNNNONOOO,NNNNOONOO,NNNNOOONO,NNNONNOOO,NNNONONOO,NNNONOONO,NNNOONNOO,NNNOONONO,NNONNNOOO,NNONNONOO,NNONNOONO,NNONONNOO,NNONONONO) - 4 pairs: 42 possible words (
NNNNNNOOOOO,NNNNNONOOOO,NNNNNOONOOO,NNNNNOOONOO,NNNNNOOOONO,NNNNONNOOOO,NNNNONONOOO,NNNNONOONOO,NNNNONOOONO,NNNNOONNOOO,NNNNOONONOO,NNNNOONOONO,NNNNOOONNOO,NNNNOOONONO,NNNONNNOOOO,NNNONNONOOO,NNNONNOONOO,NNNONNOOONO,NNNONONNOOO,NNNONONONOO,NNNONONOONO,NNNONOONNOO,NNNONOONONO,NNNOONNNOOO,NNNOONNONOO,NNNOONNOONO,NNNOONONNOO,NNNOONONONO,NNONNNNOOOO,NNONNNONOOO,NNONNNOONOO,NNONNNOOONO,NNONNONNOOO,NNONNONONOO,NNONNONOONO,NNONNOONNOO,NNONNOONONO,NNONONNNOOO,NNONONNONOO,NNONONNOONO,NNONONONNOO,NNONONONONO)
(Edit: after publishing this article I learned the language defined above forms a Dyck language, and the number of possible words in relation to the number of pairs is given by the Catalan numbers. Cool!)
This gives us a grand total of 64 legal words in our language. Looking easy so far. At this point we should also consider how many actual possibilities this entails - the number of actual different solutions we can have for a given game and these given possible words (remember we have to test them all).
Let’s call p the number of extra {N, O} pairs we have in our solution. For p = 0, we already know NNO is the only possible word. Considering each N is one of the 6 numbers we got for our game (order is important), and O can be any one of four mathematical operations, we have C(6,2) * 2 * 4 = 120.
It’s a big number for such a small word! The number of possibilities for each word in general is 4(1 + p) * 6!/(4 - p)!, because we have 1 + p operators (each can be any one of 4) and p + 2 numbers, each of which we sequentially draw from a pool of 6 with no replacement. The number of possibilities for each p, already taking into account the number of words for each case, is then:
- 0 pairs: 120 possibilities
- 1 pair: 3840 possibilities
- 2 pairs: 115,200 possibilities
- 3 pairs: 2,580,480 possibilities
- 4 pairs: 30,965,760 possibilities
- Total: 33,665,400 possibilities
This means that, in the worst case, we will search around 30 million possibilites for each game (although many of these will be culled midway through the evaluation process because of illegal intermediate results). But how many games do we have to consider?
Indexing games
Consider the case of a game with 6 small numbers. How many possiblities there are?
You may be tempted to answer 106 = 1,000,000 because there are six numbers, each one from 1 to 10. However, remember the rules: the small numbers are drawn from a pool of 20 cards, comprised of 2 cards for each number from 1 to 10. So you can’t, for example, have a game with three numbers 7.
Moreover, our calculations in the language section already take into account every possible permutation of the given numbers. For us, a game with 2 1 4 3 5 6 and a game with 6 5 4 3 2 1 are in effect the same, because they will generate the same 30 million-odd possibilities. A useful way of identifying games which are actually the same is to choose a canonical representation. In our case we will just order the input numbers. So 2 1 4 3 5 6 and 6 5 4 3 2 1 are both the “canonical game” 1 2 3 4 5 6.
If we count the possible “canonical games” for each of the possible cases (0 large 6 small, 1 large 5 small, and so on) we get the following:
- 0 large: 2850 unique games
- 1 large: 5808 unique games
- 2 large: 3690 unique games
- 3 large: 840 unique games
- 4 large: 55 unique games
- Total: 13243 unique games
The final number is surprisingly small: just over 13 thousand games need to be considered. Keep in mind that each game has a different probability of coming up: if you drew all possible games (not only the canonical ones) using all individual cards – a staggering 36,917,760 games in total – , the canonical game 1 1 2 2 3 3 would come up 720 times. It’s exceedingly more rare than, for example, 1 2 3 4 5 6, which would come up 46,080 times. These frequencies need to be tracked, so that in the end we can come up with right values for the solving probabilities.
Results
You can get the data files for running your own analyses and the (slightly crude) Python code for the calculations at this github repo.
The images linked below are a graphical representation of the results. Each pixel in the horizontal direction is a result value, from 100 to 999 (900 pixels in total). Each pixel in the vertical direction represents a canonical game, in lexicographical order (13,243 total for the complete set). A white pixel represents full points, green is 7, red is 5, and black is nothing.
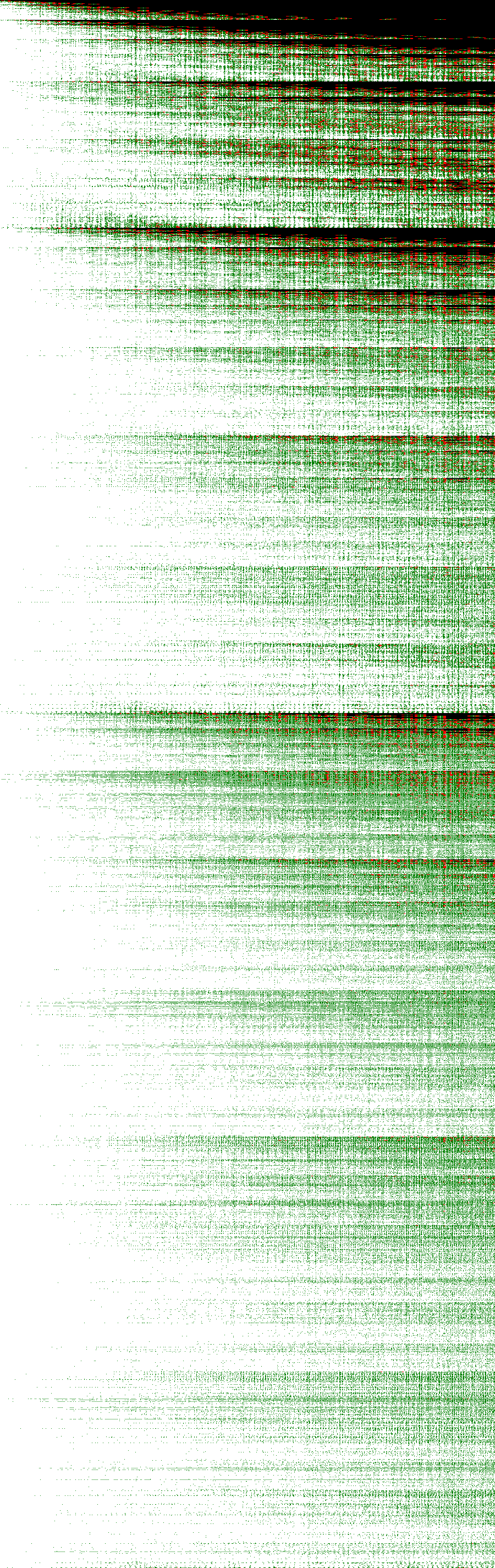{kind=link}
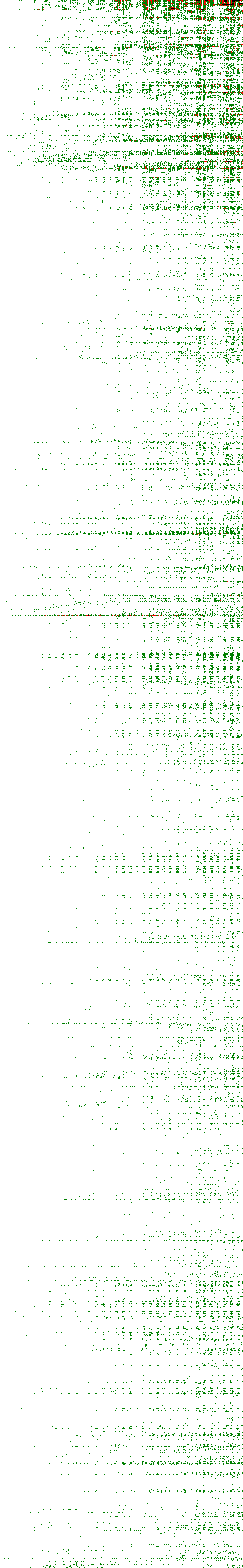{kind=link}
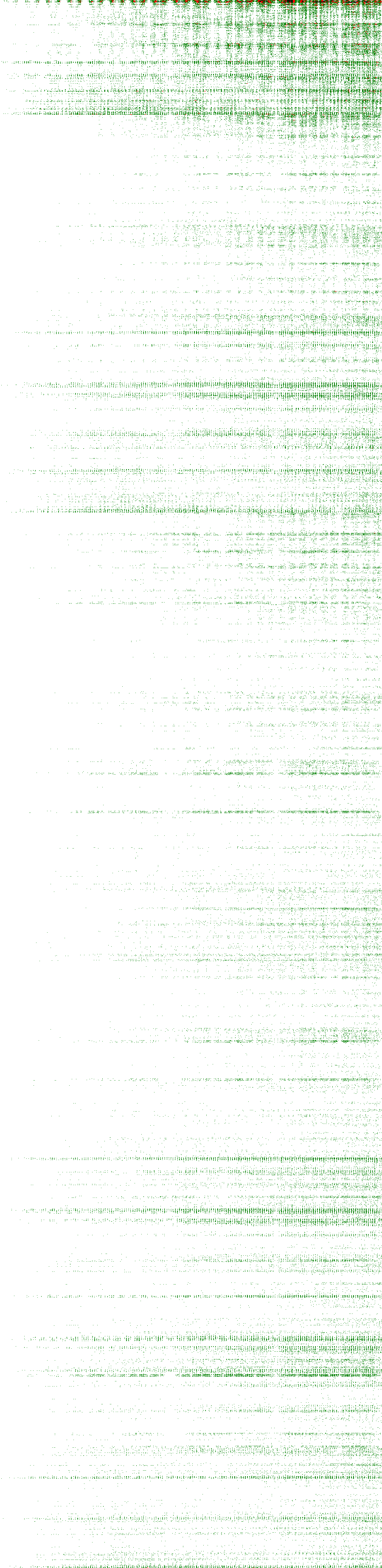{kind=link}
{kind=link}
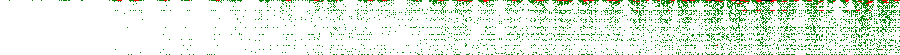{kind=link}
{kind=link}
Some structure is noticeable, especially near the beginning of the 3:3 set (“arrows” or “christmas trees”). It’s also clear that the area near the beginning of the sets is always the worst for points. This is where the lowest numbers are concentrated (because of the lexicographical ordering), and is a reflection of how bad it is to get a 1 in the draw – a 1 does not give you too much range in additions and subtractions, and is useless for multiplications and divisions. Also, it becomes obvious that low targets are easier than high targets.
The harmful effect of getting a 1 is quantified in the table below. It shows how successful your play (here a play is a concrete game case – a canonical game plus a given target) can be on average, given you got a certain number in the draw. Out of all possible plays where at least one 100 is present, 98% are solvable for maximum points. This percentage falls to just 82% when you are dealt at least one number 1.
How many large numbers should I choose?
The table below shows, for each possible selection (0 large 6 small, 1 large 5 small, …) and overall, how many % of the possible plays are able to fetch you the amount indicated in the header. This includes all possible targets for each case.
Some immediate conclusions can be drawn from this table:
- Overall in just 1.57% of the plays the contestants will be unable to compete for any points at all, which should be encouraging;
- If you do NOT choose 6 small and 0 large (clearly the poorest choice for points), this possibility all but disappears;
- 2 large, 4 small is the best choice in terms of expected points haul. Additional analysis on the data shows in this case you might be unable to score any points (that is, you get a target with no possible solutions within a distance of 10 to either side) only if you get two 1s AND:
2, 2and any 2 large numbers2, 3, 50, 1002, 4, 50, 1003, 3, 50, 1004, 4, 25, 1007, 7, 25, 100
- Martin’s selection of 4 large, 2 small was not the riskiest, but comes in a close second. Even then, the probability of his getting a play worth less than 7 points was basically nil.
Data analysis tidbits
- The game with the numbers
1 1 2 2 3 3is the only one where it’s impossible to score any points, irrespective of the target. Luckily, the chances of getting it (provided you disregarded the sound advice above and went with 6 small numbers anyway) are of 1 in 38760. - Overall there is a 6.57% chance (about 1 in 15) that the drawn game will be solvable for 10 points, no matter the target. (Incidentally, this chance goes down to 1 in 229 if you pick 6 small numbers. So don’t be that guy.)